About, Disclaimers, Contacts
"JVM Anatomy Quarks" is the on-going mini-post series, where every post is describing some elementary piece of knowledge about JVM. The name underlines the fact that the single post cannot be taken in isolation, and most pieces described here are going to readily interact with each other.
The post should take about 5-10 minutes to read. As such, it goes deep for only a single topic, a single test, a single benchmark, a single observation. The evidence and discussion here might be anecdotal, not actually reviewed for errors, consistency, writing 'tyle, syntaxtic and semantically errors, duplicates, or also consistency. Use and/or trust this at your own risk.
Aleksey Shipilëv, JVM/Performance Geek
Shout out at Twitter: @shipilev; Questions, comments, suggestions: aleksey@shipilev.net
Questions
-
What is the size of Java reference anyway?
-
What are compressed oops/references?
-
What are the problems around compressed references?
Naive Approach
Java specification is silent on the storage size for the data types. Even for primitives, it only mandates the ranges the primitive types should definitely support and their behavior of operations, but not the actual storage size. This, for example, allows boolean fields to take 1, 2, 4 bytes in some implementations.
The question of Java references size is murkier, because specification is also silent about what the Java reference is, leaving this decision to the JVM implementation. Most JVM implementations translate Java references to machine pointers, without additional indirections, which simplifies the performance story.
For example, for the simple JMH benchmark like this:
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
@Fork(3)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Benchmark)
public class CompressedRefs {
static class MyClass {
int x;
public MyClass(int x) { this.x = x; }
public int x() { return x; }
}
private MyClass o = new MyClass(42);
@Benchmark
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
public int access() {
return o.x();
}
}…the access to the field would look like this: [1]
....[Hottest Region 3]....................................................
c2, level 4, org.openjdk.CompressedRefs::access, version 712 (35 bytes)
[Verified Entry Point]
1.10% ...b0: mov %eax,-0x14000(%rsp) ; prolog
6.82% ...b7: push %rbp ;
0.33% ...b8: sub $0x10,%rsp ;
1.20% ...bc: mov 0x10(%rsi),%r10 ; get field "o" to %r10
5.60% ...c0: mov 0x10(%r10),%eax ; get field "o.x" to %eax
7.21% ...c4: add $0x10,%rsp ; epilog
0.50% ...c8: pop %rbp
0.54% ...c9: mov 0x108(%r15),%r10 ; thread-local handshake
0.60% ...d0: test %eax,(%r10)
6.63% ...d3: retq ; return %eaxNotice the accesses to fields, both reading the reference field CompressedRefs.o and the primitive field MyClass.x are just dereferencing the regular machine pointer. The field is at offset 16 from the beginning of the object, this is why we read at 0x10. This can be verified by looking into the memory representation of the CompressedRefs instance. We would see the reference field takes 8 bytes on 64-bit VM, and it is indeed at offset 16:[2]
$ java ... -jar ~/utils/jol-cli.jar internals -cp target/bench.jar org.openjdk.CompressedRefs
...
# Running 64-bit HotSpot VM.
# Objects are 8 bytes aligned.
# Field sizes by type: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 8, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
Instantiated the sample instance via default constructor.
org.openjdk.CompressedRefs object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) f0 e8 1f 57
12 4 (object header) 34 7f 00 00
16 8 MyClass CompressedRefs.o (object)
Instance size: 24 bytesCompressed References
But does that mean the size of Java reference is the same as the machine pointer width? Not necessarily. Java objects are usually quite reference-heavy, and there is pressure for runtimes to employ the optimizations that make the references smaller. The most ubiquitous trick is to compress the references: make their representation smaller than the machine pointer width. In fact, the example above was executed with that optimization explicitly disabled.
Since Java runtime environment is in full control of internal representation, this can be done without changing any user programs. It is possible to do in other environments, but you would need to handle the leakage through ABIs, etc, see for example X32 ABI.
In Hotspot, due to a historical accident, the internal names had leaked to the VM options list that control this optimization. In Hotspot, the references to Java objects are called "ordinary object pointers", or "oops", which is why Hotspot VM options have these weird names: -XX:+UseCompressedOops, -XX:+PrintCompressedOopsMode, -Xlog:gc+heap+coops. In this post we would try to use the proper nomenclature, where possible.
"32-bit" Mode
On most heap sizes, the higher bits of 64-bit machine pointer are usually zero. On the heap that can be mapped over the first 4 GB of virtual memory, higher 32 bits are definitely zero. In that case, we can just use the lower 32-bit to store the reference in 32-bit machine pointer. In Hotspot, this is called "32-bit" mode, as can be seen with logging:
$ java -Xmx2g -Xlog:gc+heap+coops ...
[0.016s][info][gc,heap,coops] Heap address: 0x0000000080000000, size: 2048 MB, Compressed Oops mode: 32-bitThis whole shebang is obviously possible when heap size is less than 4 GB (or, 232 bytes). Technically, the heap start address might be far away from zero address, and so the actual limit is lower than 4 GB. See the "Heap Address" in logging above. It says that heap starts at 0x0000000080000000 mark, closer to 2 GB.
Graphically, it can be sketched like this:
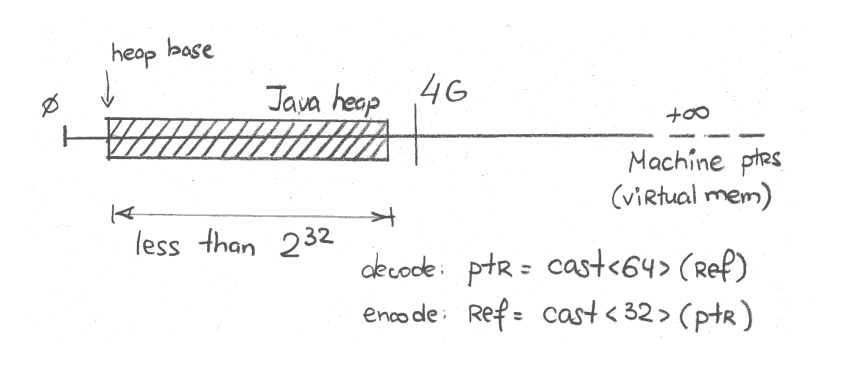
Now, the reference field only takes 4 bytes and the instance size is down to 16 bytes:[3]
$ java -Xmx1g -jar ~/utils/jol-cli.jar internals -cp target/bench.jar org.openjdk.CompressedRefs
# Running 64-bit HotSpot VM.
# Using compressed oop with 0-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
Instantiated the sample instance via default constructor.
org.openjdk.CompressedRefs object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00
4 4 (object header) 00 00 00 00
8 4 (object header) 85 fd 01 f8
12 4 MyClass CompressedRefs.o (object)
Instance size: 16 bytesIn generated code, the access looks like this:
....[Hottest Region 2]...................................................
c2, level 4, org.openjdk.CompressedRefs::access, version 714 (35 bytes)
[Verified Entry Point]
0.87% ...c0: mov %eax,-0x14000(%rsp) ; prolog
6.90% ...c7: push %rbp
0.35% ...c8: sub $0x10,%rsp
1.74% ...cc: mov 0xc(%rsi),%r11d ; get field "o" to %r11
5.86% ...d0: mov 0xc(%r11),%eax ; get field "o.x" to %eax
7.43% ...d4: add $0x10,%rsp ; epilog
0.08% ...d8: pop %rbp
0.54% ...d9: mov 0x108(%r15),%r10 ; thread-local handshake
0.98% ...e0: test %eax,(%r10)
6.79% ...e3: retq ; return %eaxSee, the access is still in the same form, that is because the hardware itself just accepts the 32-bit pointer and extends it to 64 bits when doing the access. We have got this optimization for almost free.
"Zero-Based" Mode
But what if we cannot fit the untreated reference into 32 bits? There is a way out as well, and it exploits the fact that objects are aligned: objects always start at some multiple of alignment. So, the lowest bits of untreated reference representation are always zero. This opens up the way to use those bits for storing significant bits that did not fit into 32 bits. The easiest way to do that is to bit-shift-right the reference bits, and this gives us 2(32+shift) bytes of heap encodeable into 32 bits.
Graphically, it can be sketched like this:
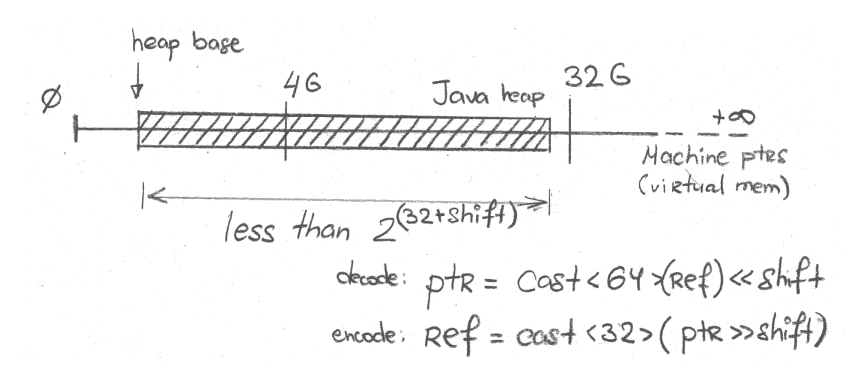
With default object alignment of 8 bytes, shift is 3 (23 = 8), therefore we can represent the references to 235 = 32 GB heap. Again, the same problem with base heap address surfaces here and makes the actual limit a bit lower.
In Hotspot, this mode is called "zero based compressed oops", see for example:
$ java -Xmx20g -Xlog:gc+heap+coops ...
[0.010s][info][gc,heap,coops] Heap address: 0x0000000300000000, size: 20480 MB, Compressed Oops mode: Zero based, Oop shift amount: 3The access via the reference is now a bit more complicated:
....[Hottest Region 3].....................................................
c2, level 4, org.openjdk.CompressedRefs::access, version 715 (36 bytes)
[Verified Entry Point]
0.94% ...40: mov %eax,-0x14000(%rsp) ; prolog
7.43% ...47: push %rbp
0.52% ...48: sub $0x10,%rsp
1.26% ...4c: mov 0xc(%rsi),%r11d ; get field "o"
6.08% ...50: mov 0xc(%r12,%r11,8),%eax ; get field "o.x"
6.94% ...55: add $0x10,%rsp ; epilog
0.54% ...59: pop %rbp
0.27% ...5a: mov 0x108(%r15),%r10 ; thread-local handshake
0.57% ...61: test %eax,(%r10)
6.50% ...64: retqGetting the field o.x involves executing mov 0xc(%r12,%r11,8),%eax: "Taketh the ref’rence from %r11, multiplyeth the ref’rence by 8, addeth the heapeth base from %r12, and that wouldst be the objecteth that you can now readeth at offset 0xc; putteth that value into %eax, please". In other words, this instruction combines the decoding of the compressed reference with the access through it, and it is done in one sway. In zero-based mode, %r12 is zero, but it is easier on code generator to emit the access involving %r12 nevertheless. The fact that %r12 is zero in this mode can be used by code generator in other places too.
To simplify the internal implementation, Hotspot usually carries only uncompressed references in registers, and that is why the access to field o is just the plain access from this (that is in %rsi) at offset 0xc.
"Non-Zero Based" Mode
But zero-based compressed references still rely on assumption that heap is mapped at lower addresses. If it is not, we can just make heap base address non-zero for decoding. This would basically do the same thing as zero-based mode, but now heap base would mean more and participate in actual encoding/decoding.
In Hotspot, this mode is called "Non-zero base" mode, and you can see it in logs like this:[4]
$ java -Xmx20g -XX:HeapBaseMinAddress=100G -Xlog:gc+heap+coops
[0.015s][info][gc,heap,coops] Heap address: 0x0000001900400000, size: 20480 MB, Compressed Oops mode: Non-zero based: 0x0000001900000000, Oop shift amount: 3Graphically, it can be sketched like this:
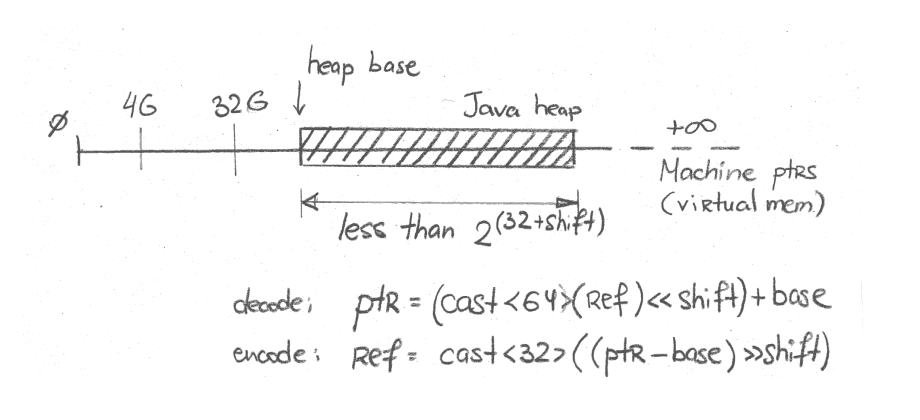
As we suspected earlier, the access would look the same as in zero-based mode:
....[Hottest Region 1].....................................................
c2, level 4, org.openjdk.CompressedRefs::access, version 706 (36 bytes)
[Verified Entry Point]
0.08% ...50: mov %eax,-0x14000(%rsp) ; prolog
5.99% ...57: push %rbp
0.02% ...58: sub $0x10,%rsp
0.82% ...5c: mov 0xc(%rsi),%r11d ; get field "o"
5.14% ...60: mov 0xc(%r12,%r11,8),%eax ; get field "o.x"
28.05% ...65: add $0x10,%rsp ; epilog
...69: pop %rbp
0.02% ...6a: mov 0x108(%r15),%r10 ; thread-local handshake
0.63% ...71: test %eax,(%r10)
5.91% ...74: retq ; return %eaxSee, the same thing. Why wouldn’t it be. The only hidden difference here is that %r12 is now carrying the non-zero heap base value.
Limitations
The obvious limitation is the heap size. Once the heap size gets larger than the threshold under which compressed references are working, a surprising thing happens: references suddenly become uncompressed and take twice as much memory. Depending on how many references you have in the heap, you can have a significant increase in the perceived heap occupancy.
To illustrate that, let’s estimate how much heap is actually taken by allocating some objects, with the toy example like this:
import java.util.stream.IntStream;
public class RandomAllocate {
static Object[] arr;
public static void main(String... args) {
int size = Integer.parseInt(args[0]);
arr = new Object[size];
IntStream.range(0, size).parallel().forEach(x -> arr[x] = new byte[(x % 20) + 1]);
System.out.println("All done.");
}
}It is much more convenient to run with Epsilon GC, which would fail on heap exhaustion, rather than trying to GC its way out. There is no point in GC-ing this example, because all objects are reachable. Epsilon would also print heap occupancy stats for our convenience.[5]
Let’s take some reasonable amount of small objects. 800M objects sounds enough? Run:
$ java -XX:+UseEpsilonGC -Xlog:gc -Xlog:gc+heap+coops -Xmx31g RandomAllocate 800000000
[0.004s][info][gc] Using Epsilon
[0.004s][info][gc,heap,coops] Heap address: 0x0000001000001000, size: 31744 MB, Compressed Oops mode: Non-zero disjoint base: 0x0000001000000000, Oop shift amount: 3
All done.
[2.380s][info][gc] Heap: 31744M reserved, 26322M (82.92%) committed, 26277M (82.78%) usedThere, we took 26 GB to store those objects, good. Compressed references got enabled, so the references to those byte[] arrays are smaller now. But let’s suppose our friends who admin the servers said to themselves: "Hey, we have a gigabyte or two we can spare for our Java installation", and have bumped the old -Xmx31g to -Xmx33g. Then this happens:
$ java -XX:+UseEpsilonGC -Xlog:gc -Xlog:gc+heap+coops -Xmx33g RandomAllocate 800000000
[0.004s][info][gc] Using Epsilon
Terminating due to java.lang.OutOfMemoryError: Java heap spaceOopsies. Compressed references got disabled, because heap size is too large. References became larger, and the dataset does not fit anymore. I would say this again: the same dataset does not fit anymore just because we requested the excessively large heap size, even though we don’t even use it.
If we try to figure out what is the minimum heap size required to fit the dataset after 32 GB, this would be the minimum:
$ java -XX:+UseEpsilonGC -Xlog:gc -Xlog:gc+heap+coops -Xmx36g RandomAllocate 800000000
[0.004s][info][gc] Using Epsilon
All done.
[3.527s][info][gc] Heap: 36864M reserved, 35515M (96.34%) committed, 35439M (96.13%) usedSee, we used to take ~26 GB for the dataset, now we are taking ~35 GB, almost 40% increase!
Conclusions
Compressed references is a nice optimization that keeps memory footprint at bay for reference-heavy workloads. The improvements provided by this optimization can be very impressive. But so can be the surprises when this enabled-by-default optimization stops working due to heap size and/or other environmental problems.
Knowing how this optimization works, when it breaks, and how to deal with breakages is important as heap sizes reach the interesting thresholds of 4 GB and 32 GB. There are ways to alleviate this breakage by fiddling with object alignment, which we would take on in "Object Alignment" quark.
But one lesson is clear: it is sometimes good to over-provision the heap for the application (makes GC life easier, for example), but at the same time this over-provisioning should be done with care, and smaller heap may mean more free space available.